Upload a Csv File Each Line as a Part + Multipart Upload S3 Java
AWS S3 Multipart Upload/Download using Boto3 (Python SDK)
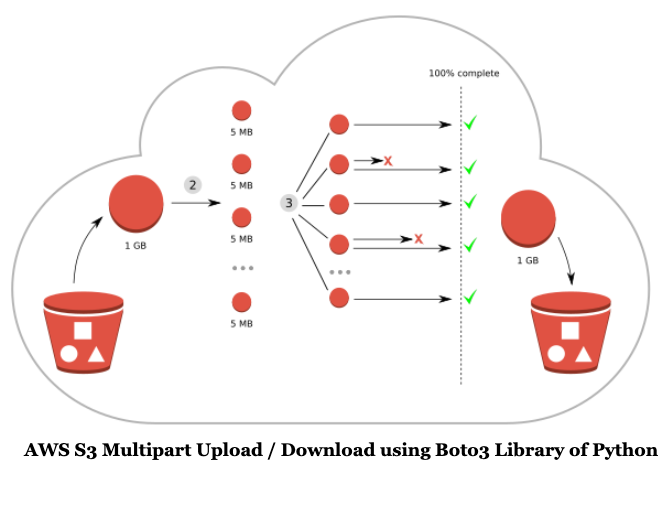
We all are working with huge data sets on a daily basis. Office of our job description is to transfer data with low latency :). Amazon Simple Storage Service (S3) can store files upwards to 5TB, yet with a single PUT operation, nosotros can upload objects up to 5 GB only. Amazon suggests, for objects larger than 100 MB, customers should consider using the Multipart Upload capability.
AWS SDK, AWS CLI and AWS S3 Balance API can be used for Multipart Upload/Download. For CLI, read this blog post, which is truly well explained.
We volition exist using Python SDK for this guide. Before we start, y'all need to have your surround ready to work with Python and Boto3. If you oasis't gear up things upwards yet, please check out my previous weblog mail service here.
Starting time, we demand to make certain to import boto3; which is the Python SDK for AWS. At present create S3 resource with boto3 to interact with S3:
import boto3 s3_resource = boto3.resources('s3')
When uploading, downloading, or copying a file or S3 object, the AWS SDK for Python automatically manages retries, multipart and not-multipart transfers. In order to achieve fine-grained control, the default settings can be configured to meet requirements. TransferConfig object is used to configure these settings. The object is so passed to a transfer method (upload_file, download_file) in the Config= parameter.
from boto3.s3.transfer import TransferConfig config = TransferConfig(multipart_threshold=1024 * 25,
max_concurrency=ten,
multipart_chunksize=1024 * 25,
use_threads=True)
Hither's an caption of each element of TransferConfig:
multipart_threshold: This is used to ensure that multipart uploads/downloads but happen if the size of a transfer is larger than the threshold mentioned, I have used 25MB for example.
max_concurrency: This denotes the maximum number of concurrent S3 API transfer operations that will exist taking identify (basically threads). Set this to increase or subtract bandwidth usage.This attribute's default setting is 10.If use_threads is set to False, the value provided is ignored.
multipart_chunksize: The size of each office for a multi-role transfer. Used 25MB for case.
use_threads: If True, parallel threads volition exist used when performing S3 transfers. If False, no threads volition be used in performing transfers.
After configuring TransferConfig, lets telephone call the S3 resource to upload a file:
bucket_name = 'kickoff-aws-bucket-ane' def multipart_upload_boto3():file_path = bone.path.dirname(__file__) + '/multipart_upload_example.pdf'
key = 'multipart-test/multipart_upload_example.pdf's3_resource.Object(bucket_name, key).upload_file(file_path,
ExtraArgs={'ContentType': 'text/pdf'},
Config=config,
Callback=ProgressPercentage(file_path)
)
- file_path: location of the source file that we want to upload to s3 bucket.
- bucket_name: name of the destination S3 saucepan to upload the file.
- key: name of the central (S3 location) where you want to upload the file.
- ExtraArgs: set up extra arguments in this param in a json string. You can refer this link for valid upload arguments.
- Config: this is the TransferConfig object which I just created above.
Similarly, for downloading file:
def multipart_download_boto3():file_path = os.path.dirname(__file__)+ '/multipart_download_example.pdf'
file_path1 = os.path.dirname(__file__) primal = 'multipart-test/multipart_download_example.pdf's3_resource.Object(bucket_name, fundamental).download_file(file_path,
Config=config,
Callback=ProgressPercentage(file_path1)
)
-bucket_name: proper name of the S3 saucepan from where to download the file.
- key: proper name of the key (S3 location) from where yous want to download the file(source).
-file_path: location where y'all want to download the file(destination)
-ExtraArgs: ready extra arguments in this param in a json string. You can refer this link for valid upload arguments.
-Config: this is the TransferConfig object which I just created to a higher place.
Please note that I take used progress callback so that I tin can
track the transfer progress. Both the upload_file and
download_file methods accept an optional callback parameter. This ProgressPercentage class is explained in Boto3 documentation.
Interesting facts of Multipart Upload (I learnt while practising):
- In order to bank check the integrity of the file, earlier you upload, you can calculate the file's MD5 checksum value every bit a reference. Say you want to upload a 12MB file and your office size is 5MB. Calculate 3 MD5 checksums corresponding to each office, i.e. the checksum of the first 5MB, the 2nd 5MB, and the last 2MB. Then accept the checksum of their chain. Since MD5 checksums are hex representations of binary information, just brand sure you have the MD5 of the decoded binary chain, non of the ASCII or UTF-8 encoded chain. When that's washed, add a hyphen and the number of parts to go the ETag of the terminal object in S3.
- For a traditional PUT request, ETag of the object is the MD5 checksum of the file. However, for multipart uploads Etag is calculated based on a dissimilar algorithm.
Go along exploring and tuning the configuration of TransferConfig. Happy Learning!
For entire code reference, visit github.
hudsonthenecolasty1936.blogspot.com
Source: https://medium.com/analytics-vidhya/aws-s3-multipart-upload-download-using-boto3-python-sdk-2dedb0945f11
0 Response to "Upload a Csv File Each Line as a Part + Multipart Upload S3 Java"
Post a Comment